The messy data sources behind "Mapping diversity"
We have been toying with the idea of doing large-scale open-ended analysis of street names across Europe for quite some time.
Back in 2019, I quickly built an R package that facilitated retrieving the names of streets used in a municipality, tried to guess which were humans and the relative gender (simplistically operationalised as “sex at birth”), and provided a basic interface to check the data (here’s a walkthrough of the process).
castarter - content analysis starter toolkit for R
castarter is a more modern, fully-featured, and consistent iteration of castarter - Content Analysis Starter Toolkit for the R programming language (a previous iteration is still available as castarter.legacy. It facilitates text mining and web scraping by taking care of many of the most common file management issues, keeps tracks of download advancement in a local database, facilitates extraction through dedicated convenience functions, and allows for basic exploration of textual corpora through a Shiny interface.

tidywikidatar - Interact with Wikidata and get tidy data frames in response
The goal of tidywikidatar is to facilitate interaction with Wikidata:
all responses are transformed into data frames or simple character vectors it is easy to enable efficient caching in a local sqlite database (integration with other databases is also available) If you want to benefit of the wealth of information stored by Wikidata, but you do not like SPARQL queries and nested lists, then you may find tidywikidatar useful.

tifkremlinen
tifkremlinen is a package providing a single dataset - kremlin_en - including all contents published on the English-language version of kremlin.ru starting with 31 December 1999 and until 31 December 2020. Yearly updates will likely be made available.
Link to repo on GitHub
Link to official version of dataset with all details

The data you need to win the Olympics if you go NUTS
When everybody’s moved by the contagious joy of two athletes making history by agreeing to share an Olympic gold medal, the data analyst thinks: “two gold medals for the same competition? is this going to break my dashboard?”
"Can we have two gold? 🥇"
"Let's make history, man"#GOLD #Tokyo2020 pic.twitter.com/y2PATi92Jq
— Giuseppe Famà (@FamaNelMondo) August 1, 2021 In my case, I was worried it would break my parsing script.
Russophobia in Russian official statements and media. A word frequency analysis
N.B. For a better formatted version of this post, consider following this link
References to ‘anti-Russian sentiments’ or ‘Russophobia’ - have a long history that dates back to the 19th century (Feklyunina 2012; Darczewska and Żochowski 2015). However, in recent years references to the alleged spread of ‘Russophobia’ in the West have apparently become more common and more politically consequential, in particular after Russia’s annexation of Crimea and the war in the Donbas (Darczewska and Żochowski 2015).
Finding gendered street names. A step-by-step walkthrough with R
EDJNet has recently released the first pilot version of “Mapping diversity”: it shows for the main city in each of Italy’s regions how many streets are dedicated to men and women and includes details about who these streets were dedicated to. In a visually impressive format developed by Sheldon.studio with text and analysis by Alice Corona, it highlights that many more streets are dedicated to men than to women, and that many of those women are Catholic saints or other religious figures.
Google Earth Studio as a data visualisation tool (with R)
Google Earth Studio is a fancy tool that allows for the creation of videos of stunning quality, by making it possible to create smooth transitions between locations across the globe, zooming in closer to the ground, and showing mountains and cities in 3D.
Here is their own promo video:
However, so far I have not really seen it used for data visualisation, nor I have seen any post online discussing how to use Google Earth Studio with data.
Beautiful Gantt charts with ggplot2
A new straightforward online interface that makes it easy to create and customise decent-looking charts for grant applications

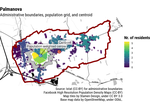
How to find the population-weighted centre of local administrative units
A structured approach and a new R package to deal with a recurrent question