I am senior researcher and data analyst at OBCT / CCI.
I have been working on a research project dedicated to text as data (and data in the text): find out more on tadadit.xyz.
For a long time, I have been conducting research on post-Soviet affairs, focusing in particular on de facto states. I have been visiting Russia and other post-Soviet countries since 2000, and I speak fluently Russian and Romanian. I am a member of the board of directors of Asiac, the Italian Association for the study of Central Asia and the Caucasus. I have been lecturer at the University of Trento and at Dublin City University.
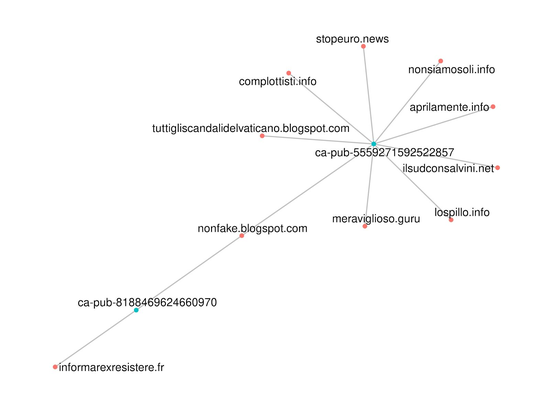
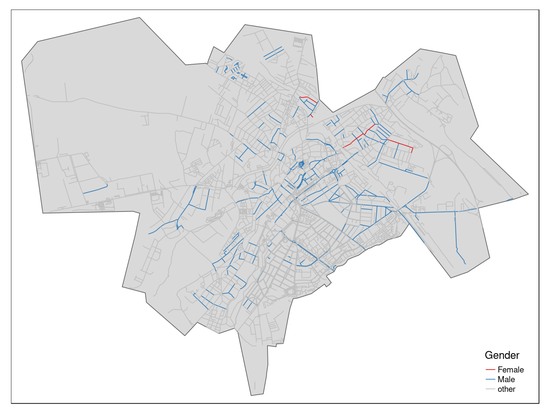
In recent years, I have increasingly been working on structured approaches for analysing online sources in conflict studies and international relations, data collection methods, and related ethical issues. I have also been working as a data analyst and consultant, crunching data at the European Data Journalism Network ( EDJNet), writing code and developing packages in the R programming language, and working on data visualisation and geographic data analysis.
I occasionally post on my data visualisation blog:
the codebase.
Find me micro-blogging @giocomai@mastodon.social.
Interests
- data crunching, data visualisation and geocomputation
- peace and conflict studies
- data collection methods and ethics in research
- structured analysis of web contents
- Post-Soviet affairs and de facto states
- digital humanities
- R programming
Education
-
PhD, Law and Government, 2018
Dublin City University
-
MA, area studies, 2006
MIREES - Interdisciplinary Research and Studies on Eastern Europe
-
BA, political science, 2004
University of Bologna